
Python
输入输出
标准输出
语法
print('',[sep = ' '],[end = '\n'],[file = None])
1 | print( |
标准输入
语法
input()1
input('这是一条输入语句')
通过键盘输入一些内容
变量
变量名只包含数字,字母,下划线 不能以关键字命名
不能以数字开头
PEP8命名规范
1.恒定量(常量)使用全大写与下划线:比如规定的不可更改的变量的值
2.私有变量使用前导下划线和小写,如:_message
3.一般的变量则应该: 全小写,用下划线隔开 表示类型的字母放在最前面 作用或要完成的工作则在中间 属于谁 放在最后,或可省略 例如: numpy_creat_data_set_test表示的意思是: 该变量是Numpy类型,被创建为一个数据 集,用于测试(test这个函数的内部变量) _4.当一个变量被用于保存于布尔值时,做好使用is或has作为前缀,这样更易于理解
5.当一个变量被用于保存序列时,最好使用复数形式
6.当一个变量被用于临时保存时,最好加上temp_的前缀
7.当一 个变量被用于作为字典时,应该使用显示名称,如一个用来保存个人地址的变量:person_address
8.应当避免使用通用 名称,现有名称(已有名称,变量i,j可以循环使用), 避免关键字,非得使用可以使用后缀下划线
9.类名使用驼峰命名法,当 定义的是模块的私有类时,还可能有一个前导下划线。
- 变量名全小写,单词使用下划线分隔
- 表示类型的字母放在最前面
- 作用或要完成的工作放在中间
- 属于谁放在最后,或可省略
数据类型
基本数据类型
基础类型可以分为四个类型
数值类型的复杂度是bool < int < float
在混合类型的表达式中,Python首先将被操作的对象(数字)转换成其中最复杂的操作对象(数字)的类型,然后再 对相同类型的操作对象(数字)进行数学运算
使用type(变量名)查看变量类型
整型(Int)
Python对于整型的定义只有int类型
数值一般为十进制,也可以表示成二进制,八进制,十六进制
- 二进制: 以
0b或0B开头,后面是二进制数01010 - 八进制: 以
0o或0O开头,后面是八进制数0 ~ 7 - 十六进制: 以
0x或0X开头,后面是十六进制数0 ~ 9,a ~ f或A ~ F
在编译运行的时候会自动转换成十进制数
例如
int_age = 15那么
type(age)的结果就是int- 二进制: 以
浮点(Float)
Python对于浮点数的定义只有float类型
可以省略小数点前或后的0
取值范围是
-10 ^ 308 ~ 10 ^ 308,如若超过取值范围会出现溢出错误布尔(Bool)
也称作逻辑常量,只有True和False两个值
其False对应0,True对应非0值(1)
复数(Complex)
表示方式为
实部 + 虚部,其虚部以j或J作结尾可以使用
complex()函数创建复数复数的运算
(2 + 3j) + (2 + 1j)的值是4 + 4j
组合数据类型
组合数据是存储多个基本数据类型的一种数据结构
列表(list)
列表中的元素类型可以是相同的也可以是不同的
列表中的元素既可以是基本数据类型也可以是组合数据类型
语法格式:
列表名[元素1,元素2,元素3,元素4]例:
names = ['张三','李四','王五']其数据类型是:
<class 'list'>字典(dict)
如有
key : value组合的数据类型可以使用字典进行储存字典的key不能重复
语法格式:
字典名 = {key1:value1,key2:value2}例:
user_info = '姓名':'张三','年龄':'20'其数据类型是
<class 'dict'>元组(tuple)
语法格式:
元组名 = ('张三','李四','王五')集合(set)
无序的,唯一的,不可变类型
集合中的元素不保存存储的顺序
集合中的元素是不能重复的
集合中的元素是无法被修改的
语法格式:
集合名 = {'张三','李四','王五'}
运算符
| 运算符 | 描述 | 示例(a = b = 5) |
|---|---|---|
| + | 加号 | 两个对象相加 a+b 的结果为10 |
| - | 减号 | 取一个数的负数,或一个数减去另一个数 a - b的结果为-10 |
| * | 乘号 | 两个数相乘或返回一个被重复n次的字符串 a * b的结果为25 |
| ** | 幂运算 | 返回a的b次幂,即5^5的结果是3125 |
| / | 除号 | 返回a除以b的结果1.0 返回包含任何余数的浮点结果 |
| // | 真除运算(floor) | 返回a除以b的结果1 若两数为int则返回int 否则为float类型 |
| % | 取余 | 返回除法的余数a % b的结果为0 |
对于字符串而言,加法的操作是让两个字符串连接,乘法的操作是让字符串重复输出n次
字符串无法做减法运算,除法运算
1 | # 判断12是否为偶数 |
逻辑运算符
短路运算:一旦前面的表达式可以完成整个表达式关系的计算,那么后续的计算就不会继续判断
在and中,只要有一个False则整个表达式的结果就是False
在or中,只要有一个True则整个表达式的结果就是True
| 运算符 | 逻辑表达式 | 描述 | 示例 |
|---|---|---|---|
| and | x and y | 布尔”与” 如果 x 为 False,x and y 返 回 False,否则它返回 y 的计算值。 | x = False y = True b = x and y print(b) |
| or | x or y | 布尔”或” 如果 x 是 True,它返回 True,否则它返回 y 的计算值。 | x = True y = False b = x or y print(b) |
| not | not x | 布尔”非” 如果 x 为 True,返回 False。如果 x 为 False,它返回 True。 | x = True b = not x print(b) |
复合赋值运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c = a 等效于 c = c a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
正则
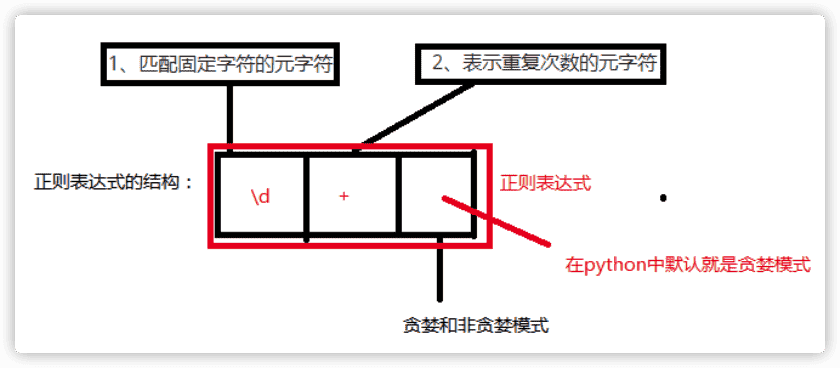
匹配固定字符的元字符
| 标识符 | 含义 |
|---|---|
| \b | 匹配单词的开和结束 Hello World |
| \d | 匹配数字 |
| \w | 匹配字母,数字,下划线 |
| \s | 匹配任意空白,包括空格,制表符 |
| [a-z] | 匹配字符a到z之间的26个小写字母中的任意一个字母 |
| . | 匹配换行符以外的任意一个字符 |
表示重复次数的元字符
| 标识符 | 含义 |
|---|---|
| ? | 重复匹配0次到1次 |
| * | 重复匹配0次或更多次 |
| + | 重复匹配1次或更多次 |
| {n , } | 重复n次或更多次 |
| {n , m} | 重复n 到 m次 |
使用方法
导包
import re将一个正则表达式编译成一个pattern对象(正则表达式规则模式对象)
pattern = re.compile('正则表达式','匹配的模式',)匹配模式: re.S 可以匹配任意字符
使用pattern对象,进行匹配文本
匹配的方法
pattern.match/search/findall/sub/split
匹配方法
match方法: 默认从开头位置匹配,只匹配一次,返回match对象
1
2
3
4
5match对象 = pattern.match(
'待匹配的字符串',
'匹配的开始位置', 默认为0
'匹配的结束位置', 默认就是字符串的结尾
)search方法: 默认全文匹配,值匹配一次,全文都找到返回match对象,全文都没找到就返回None
1
2
3
4
5search对象 = pattern.search(
'待匹配的字符串',
'匹配的开始位置', 默认就是0
'匹配的结束为止', 默认就是字符串的结尾
)findall方法: 全文匹配,匹配多次,将匹配到的数据存放到一个list中返回
1
2
3
4
5list = pattern.findall(
'待匹配的字符串',
'匹配的开始为止', 默认为0
'匹配的结束位置', 默认是字符串的结尾
)split方法: 切分字符串
1
2
3
4list = pattern.split(
'切分的字符串',
'切分次数', 默认是全部切分
)sub方法: 替换字符串
1
2
3
4str = pattern.sub(
'替换的内容', 想要用啥替换
'替换的目标', 替换哪个字符串
)
贪婪和非贪婪
- 贪婪和非贪婪表示的正则匹配次数
- 正则匹配模式是贪婪模式,非贪婪模式用?控制
- 贪婪模式下,匹配的次数取决于最大值,非贪婪模式下匹配次数取决于最小值